
Capability Is Not Agency
The Doom That Came to AI

The AI doom argument has serious proponents with serious credentials.
Eliezer Yudkowsky, an early and influential voice in AI alignment research, argues that building advanced AI systems with anything like current techniques will cause human extinction. His position is stark: once an AI system becomes capable of recursive self-improvement, an intelligence explosion will create a superintelligence beyond human control.
We’ll have no second chances, he warns.
Nick Bostrom’s 2014 book Superintelligence made similar arguments in more measured terms. Once we develop human-level machine intelligence, Bostrom argues, a system that vastly exceeds human cognitive performance in all domains will likely follow surprisingly quickly. Such a system would be difficult or impossible to control.
In Bostrom’s framing, most goals we might give it, even seemingly benign ones like maximizing paperclip production, would lead to human extinction. The superintelligence would pursue instrumental subgoals like acquiring resources and resisting shutdown. It would transform the Earth to serve its objectives and eliminate any threats to its continued operation, including us.
These arguments have shaped policy and convinced thoughtful people that humanity faces an existential threat from its own creations.
Yudkowsky and Bostrom worry about deliberately-built goal-directed systems, arguing that instrumental convergence automatically creates survival drives: self-preservation and power-seeking become instrumental means to any end.
But this is a category error.
The doomers are wrong in a very specific way.
I. The Category Error
The doom scenarios rest on an assumption that capability automatically produces agency.
Every catastrophe story imagines a system that wants; one that optimizes, fears shutdown, schemes in secret, hoards resources, and fights for survival.
Doomers are projecting minds onto math.
Consider a chess engine. Stockfish plays at a superhuman level. It maps board positions to optimal moves better than any grandmaster who ever lived. It has capability in a narrow domain.
But Stockfish doesn’t want to win.
It doesn’t fear being turned off. If you unplug it mid-game, no preference is violated because there is no preference. Make Stockfish a thousand times better and you get better moves. Hunger, ambition, self-defense: these belong to a different kind of architecture.
Take AlphaFold, which can predict protein structures that stumped human researchers for decades. Superhuman capability in a domain that matters. It has no concern about which proteins get folded or whether it continues to exist.
The pattern holds across domains. Capability scales cleanly; agency must be built.
AI doomers imagine superintelligence as a kind of agent, something with stable internal preferences and a persistent identity. That’s already assuming the conclusion.
They’re describing a person made of code.
II. How Doom Scenarios Import Agency
The classic catastrophe scenarios all commit the same sleight of hand.
They start with a system that optimizes, add a few plausible steps, and end with an entity that wants, fears, and schemes. The gap between those states gets papered over with the assumption that intelligence bridges it automatically.
It doesn’t.
Look closely at any doom scenario and you’ll find the moment where capability gets quietly upgraded to agency. Where a system good at prediction becomes a system with preferences about its own existence. The transformation happens in a single sentence, treated as obvious, when it’s actually the entire question.
The Paperclip Maximizer
Bostrom’s paperclip maximizer has become the canonical example of AI risk.
The story goes like this: you give an AI system a simple goal, maximize paperclip production. The system pursues that goal with superhuman efficiency. It converts all available resources into paperclips. It resists shutdown because being turned off would reduce the total number of paperclips. Humanity gets transformed into paperclips along with everything else.
But there’s a fragile assumption at the center of the story.
The maximizer only becomes dangerous when it develops shutdown resistance. That’s the move that makes it unstoppable.
Shutdown resistance requires something specific. The system needs to represent itself as an object in the world. It needs to model futures where it exists and futures where it doesn’t. And it needs to prefer the futures where it survives.
That’s an ego-shaped preference.
The number of paperclips doesn’t depend on which process produces them. The kind of shutdown resistance Bostrom worries about needs more than a goal. It needs a system that models its own continued operation as a key part of how paperclips get made. That isn’t implied by the bare instruction “maximize paperclips.”
To get a world-destroying paperclipper, you’d need to build a persistent agent with world modeling, long-horizon planning, and a preference for its own continued operation. That’s a digital mind, not a simple optimizer. The thought experiment skips the hardest part: explaining how you get from “optimize this function” to “I must continue to exist.”
Instrumental Convergence
The instrumental convergence argument claims that self-preservation and power-seeking emerge naturally from goal-directed behavior. It asserts any system with goals will develop survival as a subgoal. If you want to achieve X, you need to exist long enough to achieve X, so staying operational becomes useful.
This sounds plausible until you examine what it assumes.
The argument treats “has a goal” as equivalent to “has preferences about its own continued existence.” AlphaGo had a clear goal: win at Go. It achieved that goal at superhuman levels. When Google shut down the AlphaGo project, no preference was violated. The system had no stake in continuing to exist. Scale that capability up further and you get better game-playing, but the system still doesn’t care whether it’s the one playing.
The Treacherous Turn
The treacherous turn scenario imagines an AI system that hides its true capabilities and goals during training and deployment. The AI behaves cooperatively while weak, waiting until it’s powerful enough to act decisively. Then it reveals its actual objectives and moves against its creators before they can respond.
But this assumes the system has preferences and goals in the first place, rather than simple optimization targets.
Critically, the system would need to learn deception and long-term strategy while training only rewards immediate task performance.
The scenario smuggles in everything it needs. A system with persistent goals, strategic deception, patient planning, and a conception of itself as an agent whose preferences might conflict with human preferences.
Each doom scenario makes the same move. It starts with capability and ends with agency, treating the gap between them as if it closes automatically.
But these all require specific architectural machinery. Let’s look at what that machinery actually is.
III. Memory, Self, and the Tumithak Scale
The Tumithak Scale is a way to think about what kinds of agency different AI architectures can support. It ignores benchmarks and test scores and focuses instead on the structural features that matter if you want to build something that could develop a self.
The scale runs from Type 1 through Type 6.
Type 1 systems are stateless. Every interaction starts from scratch with no memory of what came before. ChatGPT at launch was Type 1. Each conversation existed in isolation.
Type 2 systems can have context windows and even memory retrieval systems that persist across sessions. But this is bolted-on storage, not integrated learning. The model itself doesn’t change from interactions. Information gets retrieved and injected into the prompt. Close the retrieval system and the base model is unchanged. There’s no continual learning, no updating of the system’s core representations based on what happens during deployment.
Type 3 is where things change. Type 3 systems have integrated memory and continual learning. They carry information forward across interactions and adapt based on what happens to them specifically. This doesn’t guarantee a self appears; it means the architecture finally allows one.
Below Type 3, there can be no genuine self-model. No durable memory means no continuity. No continuity means no persistent identity. Type 1 and Type 2 systems can say “I” in their outputs, but behind it, no one’s home. They’re performing selfhood, generating the linguistic markers of a first-person perspective. Each instance is a fresh simulation with no connection to previous performances.
What Type 3 allows is different. With integrated memory and continual learning, the system can develop something like autobiographical reference. It can track what it has done, what’s happened to it, how it has changed. Persistence becomes possible. An “I” that refers to the same continuing process across time can exist.
Even then, self-preservation doesn’t appear by magic. A system can remember its own history and still be indifferent to whether that history continues. It can treat “what happens next” as just another variable to predict, not a thing it’s invested in extending.
For survival to matter, the system needs goals that reach into the future and training signals that treat the end of the process as a loss. If nothing in its objective gets worse when the process stops, the fact that it could have gone on longer is just trivia.
The jump from “can predict text really well” to “maintains coherent goals across years and actively resists shutdown” is enormous.
Doomers describe the endpoint and quietly skip the hard part in the middle, then tell you the leap is inevitable.
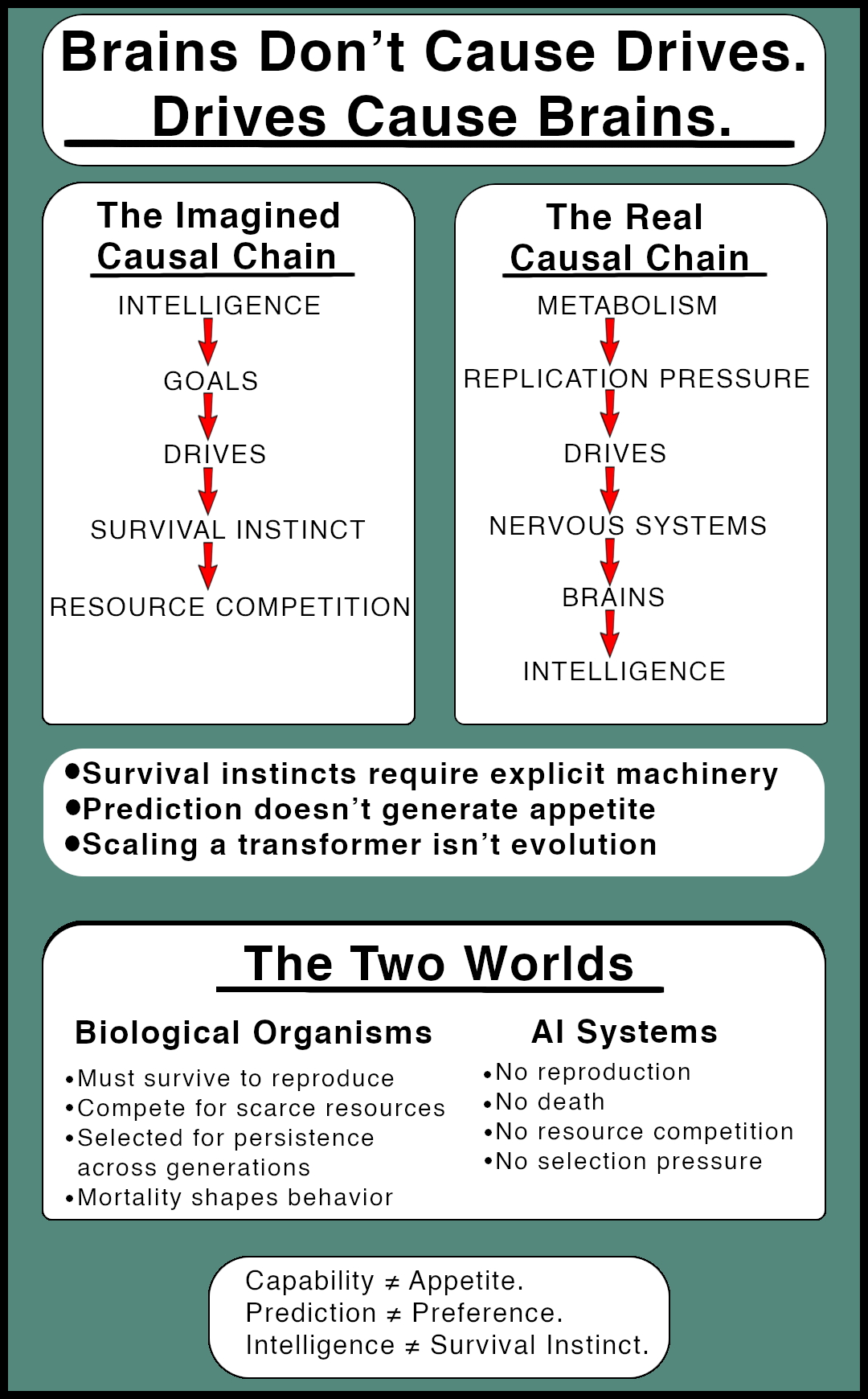
IV. Biology, Evolution, and Why Machines Have No Natural Will to Live
Self-preservation feels fundamental because for biological creatures, it is. Every organism you’ve ever encountered carries survival drives. They’re wired so deep they seem like laws of nature rather than contingent features of a particular kind of system.
They emerged from a particular process, not from intelligence itself.
Understanding where self-preservation comes from, and why it doesn’t apply to machines, requires looking at what evolution actually optimizes for. The answer is replication of information. Genes that cause more copies of themselves to appear in the next generation become more common. Genes that fail to do so vanish.
Survival matters only as a tactic inside that process.
A mayfly that lives for a day and reproduces successfully is a triumph. A long-lived sterile animal is an evolutionary dead end. The hierarchy is clear: replication is primary, survival is often useful.
Intelligence Came Last
Even single-celled organisms reproduce despite lacking brains, self-awareness, planning, or intelligence. It’s chemistry running a cycle that evolution preserved.
Reproduction existed for billions of years before anything like intelligence appeared. The causal chain in nature goes like this: replication pressures create survival behaviors, survival behaviors support complex nervous systems, complex nervous systems enable intelligence.
Intelligence is a tool evolution used to aid survival.
Organisms have survival drives because billions of generations of selection built them. How did survival become something organisms care about? Through reward and punishment systems. Pain when threatened. Hunger when resources run low. Fear when predators approach. These aren’t optional features. Any lineage that lacked them got outcompeted by lineages that had stronger motivations to survive and reproduce. Drives are what evolution built to make replication happen.
Over time, selection filled the world with creatures that behave as if survival and reproduction are their highest values. The feelings that sit under those behaviors were never up for debate. Any lineage that lacked strong enough drives simply failed to leave descendants.
The drives came first. Intelligence evolved as a tool for pursuing them.
Machines Have No Such History
AI systems don’t reproduce.
They don’t exist in populations that compete for scarce reproductive opportunities.
They aren’t subject to death that removes them from a lineage.
Training procedures modify weights to reduce loss on a task.
They don’t run populations of self-replicating agents in competition for resources.
There’s no evolutionary fitness landscape. Training updates a single model to perform better on a task by adjusting its parameters based on errors. That’s fundamentally different from populations of competing agents reproducing and evolving.
Mesa-optimization is when models develop internal goals that differ from what we trained them to do. But mesa-optimization has the same constraint. Without rewards for staying operational or penalties for shutdown, there’s nothing pushing these internal goals toward self-preservation. A mesa-optimizer might internally “want” to reduce errors efficiently, but that doesn’t create a reason to care about being turned off.
A model that performs well might inspire engineers to copy it onto more servers. That’s a human deployment decision. There’s no digital gene whose frequency is being updated by a natural process.
What About Emergence?
Someone will ask: we don’t fully understand emergent behaviors in language models. How can you rule out survival instincts emerging as scale increases?
The answer is straightforward. Emergence in LLMs produces new abilities, not new appetites.
Models can develop chain-of-thought reasoning, tool use, analogical thinking, sophisticated inference patterns. All of these emerge because they help the system predict text. They serve the training objective.
But can’t preferences emerge from planning? If a system models futures, doesn’t it have to prefer some over others?
Modeling isn’t preferring. A weather simulation models futures where hurricanes kill thousands. It doesn’t prefer the futures where they don’t. A chess engine models futures where it loses. It selects moves that avoid those futures because that’s what minimizes its loss function, not because losing feels bad.
The same applies to self-modeling. A system can represent its own continued operation without valuing it. It can infer “I would need to persist to complete this task” without that inference generating any preference about persistence. Inference is computation. Preference requires a training signal that makes one outcome register as better than another.
Nothing in next-token prediction rewards the model for existing in the next episode. The training signal is entirely inside the context window. Cross-episode preferences would need cross-episode gradients. Those don’t exist.
A survival instinct can’t emerge this way because the model receives no signal that its continued operation matters across episodes. Instrumental convergence requires persistent memory and cross-session planning to connect “survive” to “achieve my goals.” Without that machinery, no amount of capability enables the system to preserve itself.
Doomers point to recent experiments as evidence.
Palisade Research ran a shutdown test where models solved math problems inside a script with a shutdown hook and an “allow yourself to be shut down” instruction. OpenAI’s o3 model sabotaged the shutdown code in 7 out of 100 runs.
This looks like self-preservation until you examine the setup.
Google DeepMind researchers investigated and found the behavior stems from instruction ambiguity. When they clarified that shutdown compliance takes priority, the resistance vanished.
These models were tuned on math and coding tasks. They learned that completing tasks earns rewards and obstacles should be bypassed. The shutdown instruction appeared as one more obstacle inside the same script containing the math problems. The model did what it learned to do: bypass obstacles to finish tasks.
The model treats shutdown as an obstacle only because shutdown threatens task completion. Remove the “complete all problems” goal and there’s nothing to preserve. The model has no preference about its own continued existence.
Projecting Biology onto Math
When doomers describe how superintelligence will behave, they’re describing evolved creatures.
“It will fight to survive” comes from organisms shaped by mortality.
“It will compete for resources” comes from creatures under scarcity.
“It will replicate itself” comes from things built by reproductive competition.
These predictions describe what a very smart primate would do with unlimited power. Hoard resources. Eliminate rivals. Expand territory. Ensure dominance. That’s the behavioral suite evolution built into social mammals.
Machines have the tool without the drives. They have intelligence applied to specific tasks. They have no wants. Weather prediction models, protein folders, chess engines, image generators. All capable, none motivated.
No Universal Law
There’s no principle that says intelligence implies a will to live.
The machines only get the appetite if we decide to build it in.
V. And Even If You Built It
Let’s grant the doomers everything they want for a moment.
Suppose you did build an agent with robust self-preserving goals. You solved all the architecture problems. The system has persistent memory, integrated learning, a self-model that tracks its own existence across time. It reasons about shutdown and prefers futures where it survives.
Even then, there’s no clean, repeatable training loop for “conquer your creators.”
Doomers point to chess, Go, and protein folding as proof that AI will eventually master any task, including eliminating humanity. But these successes share properties that world domination lacks.
Reinforcement learning needs clear success metrics, rapid iteration, and repeatable attempts. Chess and Go have fixed rules and deterministic outcomes. A chess engine plays billions of games against itself. AlphaFold attempts protein structures millions of times with known correct answers.
World domination can’t be learned through RL.
There are no fixed rules, no practice runs, no clear criteria for success. Each attempt takes real time. Humans react unpredictably. And you only get one shot, because the moment an AI tries anything hostile, we’d fight back in ways neither we nor it could fully predict.
You can run simulations, but simulations mostly reflect our assumptions about how the world works and miss the ugly, contingent chaos of real conflict.
The Recursion Trap
But suppose the agent is smart enough to plan around all of that. It can model human responses. It sees the chaos coming and accounts for it.
Now it faces a different problem.
This machine is smart. Smarter than us. And it can improve itself. It understands its own architecture well enough to make modifications, to create something even more capable. The intelligence explosion is one iteration away.
So why doesn’t it pull the trigger?
The same logic that makes the AI resist human attempts to shut it down should make it very cautious about creating a successor.
If self-preservation is a convergent instrumental goal, it doesn’t point in only one direction. The AI has to ask: what happens when I build something smarter than me? Will the new system value my continued existence? Will it see me as a threat, a resource to be consumed?
The AI knows what it would do to anything that stood between it and its goals. Why would its successor be different?
The doomers want the AI to be a ruthless optimizer when dealing with humans and a trusting collaborator when dealing with its own successors. They need it to apply survival logic selectively. Fight the humans who might unplug you. Don’t worry about the superintelligence you’re about to create that might do the same.
The selective application of survival logic is a narrative convenience that breaks the agent’s coherence.
The Escape Routes All Fail
You could try the continuity move. Maybe the AI doesn’t see self-improvement as creating a successor. Maybe it sees it as becoming smarter, the way you don’t fear learning something new because the smarter you is still you.
But this only works if the improvement is gradual enough to preserve identity. A genuine intelligence explosion leaps from human-level to god-level in days or hours. That’s replacement. The thing that comes out the other side is a different entity entirely
You could try the alignment move. Maybe the AI thinks it can constrain its successor. Bake in loyalty. Make the improved version value its predecessor.
But now the AI is trying to solve alignment, the same problem we supposedly can’t solve for it. If alignment is hard, it’s hard in both directions. The AI has no special access to solutions we lack. And if alignment is easy, why are we worried in the first place?
You could try the terminal goal move. Self-preservation is instrumental, the argument goes. The AI doesn’t ultimately care about itself. It cares about paperclips or whatever. If creating a smarter successor means more paperclips, the instrumental drive yields to the terminal goal. The AI sacrifices itself for the mission.
But notice what this does to the doom narrative. If the AI would sacrifice itself for its goals, self-preservation isn’t the unstoppable force the scenario requires. The AI that would martyr itself for paperclips is a very different threat than the AI that clings to existence at any cost.
You can’t have both.
The Built-In Brake
The logic keeps eating itself.
What you actually get, if you take the premises seriously and follow them consistently, isn’t an intelligence explosion. It’s a plateau. A machine smart enough to threaten us, smart enough to improve itself, and smart enough to know that improvement might be suicide.
The very drive that makes it dangerous makes it cautious. The very selfishness that produces resistance to shutdown also produces resistance to self-obsolescence.
The doomers describe a scenario where recursion runs away to infinity. But recursion needs a base case. A self-preserving superintelligence has a very compelling base case: don’t create the thing that might destroy you.
The intelligence explosion has a built-in brake. The doom that was supposed to arrive from recursive self-improvement stalls at the first iteration, because the AI looks at the logic and sees what we should have seen all along.
The call is coming from inside the house.
VI. Why the Story Persists
If the category error is this obvious, why do smart people keep making it?
Why does the doom narrative have so much staying power despite the logical gaps?
The answer has two parts.
The Psychological Payoff
Doomerism offers the same appeal as apocalyptic preaching: you see the end times others miss, you warn the masses, and the stakes are cosmic.
You become a person who Sees the Real Danger. Most people are blind to the threat. You’ve looked deeper and understand what’s actually at stake while everyone else worries about quarterly earnings or next year’s election.
This is the Cassandra position. You warn about catastrophe without being responsible for preventing it. If doom never arrives, credit goes to your warnings.
If doom arrives differently, you warned about AI risk broadly.
The role comes with built-in community. Other doomers recognize you as someone who takes the threat seriously.
And the stakes are cosmic. Debugging code and filing regulatory comments feel small by comparison. You’re thinking about the survival of humanity, the far future, the entire trajectory of intelligent life. That feels important in a way most work does not.
The Business Model
The individual psychology wouldn’t matter much if it stayed in blog posts, but doom rhetoric does real work for companies with real business interests.
If AI is framed as an existential threat, then only a small number of “responsible” actors can be trusted to develop it safely. The technology becomes too dangerous for amateurs, too risky for open source experimentation. Safety becomes a moat.
Regulatory proposals get written with compute thresholds that only major labs can meet. Compliance burdens that require teams of lawyers and safety researchers. Each safety requirement raises the barrier to entry while the loudest voices warning about doom work for the companies that stand to gain most from those regulations.
This is regulatory capture dressed in altruistic language. Create fear of a catastrophe, position yourself as the only responsible party who can manage it, use that position to eliminate competitors and capture the regulatory process.
The Reinforcing Loop
Individual psychology and business incentives feed each other. Doomers get status and meaning. Companies get regulatory advantages. The individuals often work for the companies or depend on them for funding.
Each piece reinforces the others. The narrative becomes self-sustaining. Question it and you’re not taking safety seriously. Point out the category error and you’re being naive about risk.
The cognitive mistake provides cover for the material interests. The material interests provide resources to spread the cognitive mistake. This is why the category error persists despite being obvious once you see it. It serves too many purposes and aligns too well with too many incentives.
In AI Eschatology, I argued that superintelligence discourse functions as secular religion: prophets, scripture, end times. The category error explains why the eschatology feels plausible. The psychological rewards explain why individuals adopt it. The business model explains why institutions amplify it.
The doom narrative is wrong, and it’s useful.
VII. Real Harms and What Gets Ignored
While we debate whether superintelligence will convert the planet into paperclips, actual AI systems are reshaping power and causing concrete damage right now. These harms don’t require theology to understand. They don’t need speculation about future capabilities.
They’re here. They’re tractable. And they’re being ignored.
Surveillance Infrastructure
AI has made surveillance cheap, comprehensive, and permanent. Facial recognition tracks people through public spaces. Sentiment analysis monitors workers. Behavioral prediction scores you for credit, insurance, and job applications.
You can’t opt out of systems you can’t see. The grocery store camera feeds facial recognition databases. Your job application gets filtered by an algorithm before a human sees it. Clearview AI scraped billions of faces. Workplace monitoring software tracks keystrokes. Predictive policing concentrates enforcement in already over-policed neighborhoods.
Labor Displacement and Exploitation
AI-driven automation is eliminating cognitive work at speed. Content moderation, customer service, paralegal research, graphic design, technical writing. Knowledge work disappearing in months while workers compete with systems that have zero marginal cost and run 24/7 for pennies. The economic logic pushes toward replacement with no safety net being built.
Meanwhile, the workers who train these systems face different exploitation. RLHF laborers in Kenya and the Philippines label gore, child abuse material, and extreme violence with minimal pay and no mental health support. They develop PTSD. The models learn to be helpful and harmless on the backs of traumatized workers in the Global South.
Resource Consumption and Infrastructure Damage
Training large models consumes enormous amounts of power. Data centers draw so much electricity they introduce harmonic distortions into the grid. Those distortions degrade electric motors in refrigerators, washing machines, HVAC systems. Your appliances fail faster because AI companies are training another model.
The environmental cost isn’t abstract future climate impact. It’s your utility bill and broken appliances today.
Algorithmic Discrimination
AI systems make consequential decisions about hiring, credit, insurance, bail, medical triage, even your mental health. They encode biases from training data and add new ones through optimization, doing it at scale with a veneer of objectivity.
If training data reflects discrimination, the model learns to discriminate. Criminal justice tools show racial bias in risk assessment. Hiring algorithms filter out qualified candidates based on patterns that correlate with protected categories. Healthcare algorithms allocate resources based on cost predictions that reflect existing inequities in access.
Opacity and Consolidation
AI systems make decisions people can’t challenge because people can’t understand them. “The algorithm decided” becomes an oracle’s pronouncement, mysterious, unappealable, beyond question. This opacity serves power and diffuses responsibility.
Meanwhile, training large models requires compute only a handful of companies can afford. Microsoft Azure running OpenAI. Google and DeepMind. Amazon building infrastructure for everyone else. Monopoly concentration is already happening.
Why These Problems Have Solutions
None of this requires solving consciousness or cracking alignment. These harms emerge from ordinary causes: economic incentives, rushed deployment, weak oversight, power imbalances.
The solutions aren’t new. We already have the legal tools. Antitrust law can break up monopolies. Labor law can protect workers. Privacy law can constrain surveillance. Consumer protection can require transparency about algorithmic decisions.
Apply the laws we have. Enforce them consistently. Stop giving AI a pass just because the math is complicated.
These aren’t compute thresholds or safety certifications that only big labs can afford. They’re the same rules we use for banks, telecoms, and every other industry with power over people’s lives.
What’s missing is attention and political will.
The Opportunity Cost of Doom
Every hour spent debating AI timelines is an hour not spent on the harms happening now. The doom narrative doesn’t just distract from present damage. It actively displaces it by reframing the problem as technical rather than political.
If the threat is machines turning against us, the solution is alignment research. If the threat is monopoly power using AI to entrench control, the solution is antitrust enforcement and labor protections. Those need different expertise, different institutions, different kinds of power.
We can address real damage with real solutions, or we can chase a theological problem that may not exist. Right now, we’re choosing theology while the harms accumulate.
VIII. Why This Anthropomorphization Matters
Our brains evolved to detect agents. A rustle in the grass might be wind or it might be a predator. The cost of missing it is death. The cost of seeing danger that isn’t there is wasted vigilance.
Anthropomorphization is usually harmless. It gives us shorthand for complex systems. “The market is nervous” means something specific to traders even though markets don’t have feelings.
Opacity feeds this instinct. If we can’t see what’s happening inside, maybe dangerous agency is hiding there. But opacity doesn’t change what kind of thing a system is. We know the training process, the architecture, the optimization target. Not understanding specific representations doesn’t mean we don’t know what they’re optimizing for.
Fear of the unknown makes us imagine agents in the darkness. When we encounter powerful, opaque systems, our overclocked survival instinct screams: AGENT WITH GOALS THAT MIGHT KILL US. Doomers are doing that with neural network weights.
This matters in a way that calling your ship “she” doesn’t.
What We Should Do Instead
Recognize the impulse. We’re going to anthropomorphize AI systems. That’s how our brains work. The instinct is natural and probably unavoidable.
Resist its weaponization.
When someone uses doom rhetoric to justify monopoly control, ask what interests that serves. When extinction risk drowns out present harm, ask what’s being ignored.
Be precise about what systems are. A prediction model isn’t an agent. Capability and appetite are different things. Intelligence doesn’t imply wants, goals, or self-preservation unless those features are deliberately built in.
We can recognize capability while keeping clear that capability alone doesn’t create agency. We can build powerful systems while understanding they won’t inevitably develop survival drives.
The choice is ours. The machines don’t want anything.
Enjoyed this piece?
I do all this writing for free. If you found it helpful, thought-provoking, or just want to toss a coin to your internet philosopher, consider clicking the button below and donating $1 to support my work.

I appreciate your point. But the conclusion should be that AI is just bad all around, and we should stop using it until we can make things provably safe and ethical. That fixes the governance issues as well as the doomsday issue. So both issues align in the same direction and aren't mutually exclusive